

Delta’s $500M shutdown: why patch management is essential for business continuity
When a faulty Microsoft patch deployed through CrowdStrike brought down Delta Airlines’ ticketing systems in July 2024, it stranded more than 1.3 million passengers, canceled 7,000 flights, and cost the airline more than $500 million in under a week. The headlines blamed Microsoft and CrowdStrike, but Microsoft and CrowdStrike were just one link in a chain reaction of failure. Microsoft released a faulty update, CrowdStrike’s quality control missed it, and Delta’s patch automation deployed it everywhere at once.
Outages like this aren’t just technical failures — they are business continuity failures. Every grounded terminal meant stranded travelers, lost revenue, and reputational damage that no airline can afford.
Delta’s risk management mistake
A defective patch update pushed by CrowdStrike caused widespread Windows system crashes across industries. Delta was hit especially hard because its automation was configured to deploy patches across all terminals simultaneously. The automation wasn’t the issue — the configuration was. With a staggered rollout or phased deployment, Delta could have halted the patch before all of its 40,000 servers went down.
This chain reaction of failure required multiple steps. Vendors occasionally release faulty patches — nobody’s perfect. Delta’s mistake was relying on its vendors for reliability. When Delta was designing its processes, it should have accounted for the possibility of a problematic patch. Microsoft and CrowdStrike’s error may have triggered the event, but it was Delta’s internal configuration and lack of staggered testing that turned an IT incident into a massive outage.
Patch management is risk management
Rolling out patches to your systems isn’t just routine maintenance. You need to mitigate its risks. You diversify your supply chains and monitor them for disruption – you should do the same with your patch deployment processes. A single unchecked update can disrupt operations as thoroughly as a physical disaster. When governance teams include patching into their risk strategy, they turn a maintenance task into an insurance policy.
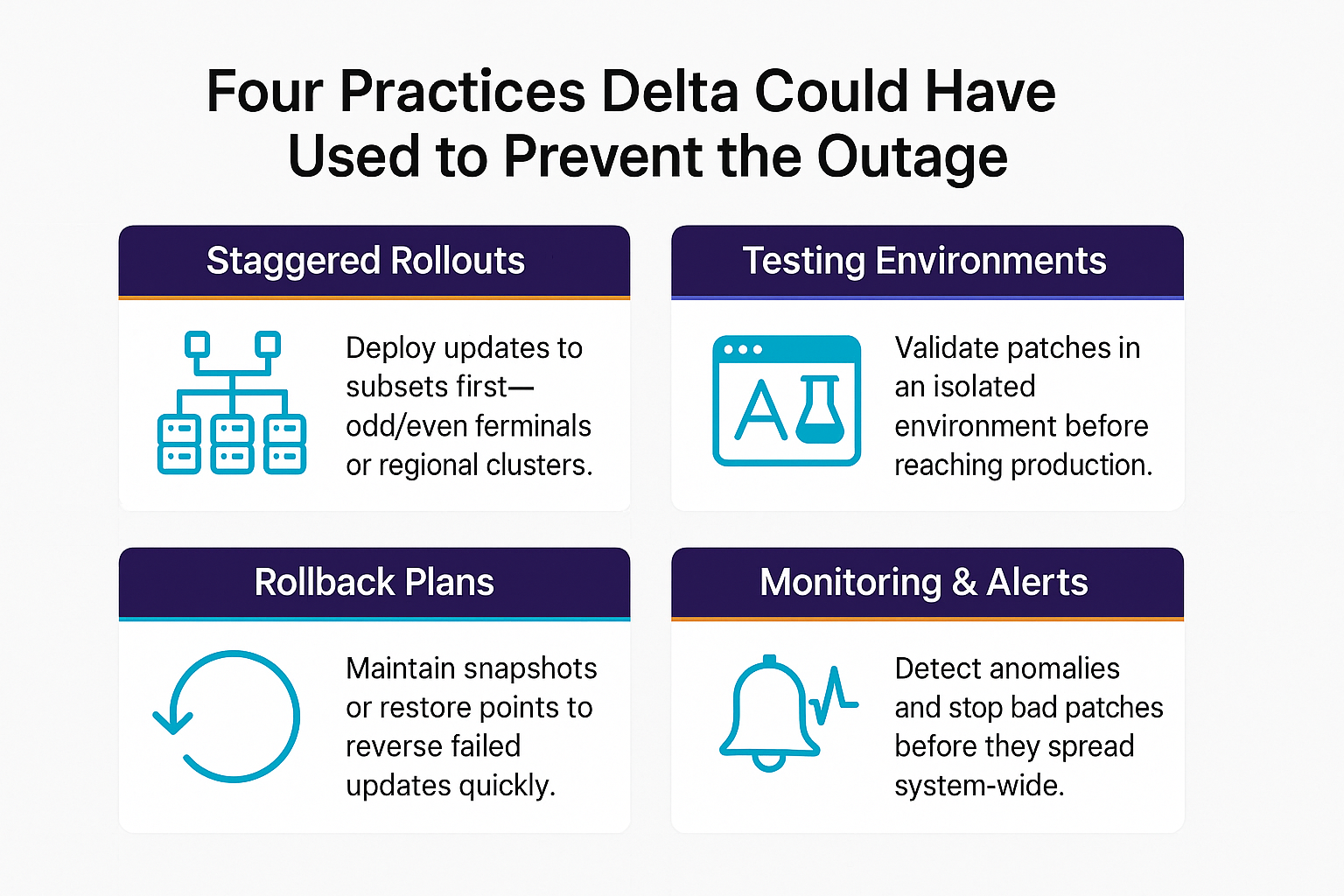
Here are four risk management practices that Delta could have used to prevent this snafu:
- Staggered rollouts. Deploy patches to subsets of your systems (odd/even terminals, geography) before rolling them out everywhere.
- Testing environments. Validate each patch in an isolated sandbox first.
- Rollback plans. Maintain snapshot or restore options to reverse failed updates quickly.
- Monitoring and alerts. Detect anomalies early to halt the spread before full impact.
The business cost of poor patch strategy
The outage cost Delta $380M in lost revenue and $170M in added expenses. Even accounting for fuel savings, it remains one of the costliest IT failures in corporate history. But the greater cost was trust — customers lost faith that Delta could manage its digital operations. If a company that size can’t keep its ticketing systems online, why would they trust it to keep their flights arriving on time…or to maintain its aircraft?
IT governance is business governance. Businesses need to see patch management as the potential risk it is, not just as an IT chore. A single configuration oversight can turn automation from a strength into a liability. For CIOs and business leaders, the takeaway is clear: the cost of staged rollouts and governance frameworks is trivial compared to half a billion dollars in losses and global headlines announcing your failure.
Is your patch management strategy resilient enough to survive a bad update?
When your IT systems are at risk, your entire business is. Let’s talk about building governance practices that keep your business running — even when your vendors falter.





